Lecture 3: Species Distribution Patterns

This material must be reviewed by BCB743 students in Week 1 of Quantitative Ecology.
Univariate diversity measures such as Simpson and Shannon diversity have already been prepared from species tables, and we have also calculated measures of
Let’s shine the spotlight to additional views on ecological structures and the ecological processes that structure the communities—sometimes we will see reference to ‘community or species formation processes’ to offer mechanistic views on how species come to be arranged into communities (the aforementioned turnover and nestedness-resultant
You will already be familiar with the paper by Shade et al. (2018). Several kinds of ecological patterns are mentioned in the paper, and they can be derived from a species table with abundance data (but not presence-absence data!). The patterns that can be derived from such a table include (see Figure 1 below), and they are as follows:
- Species-abundance distribution
- Occupancy-abundance curves
- Species-area curves
- Rarefaction curves
- Distance-decay curves
- Elevation gradients
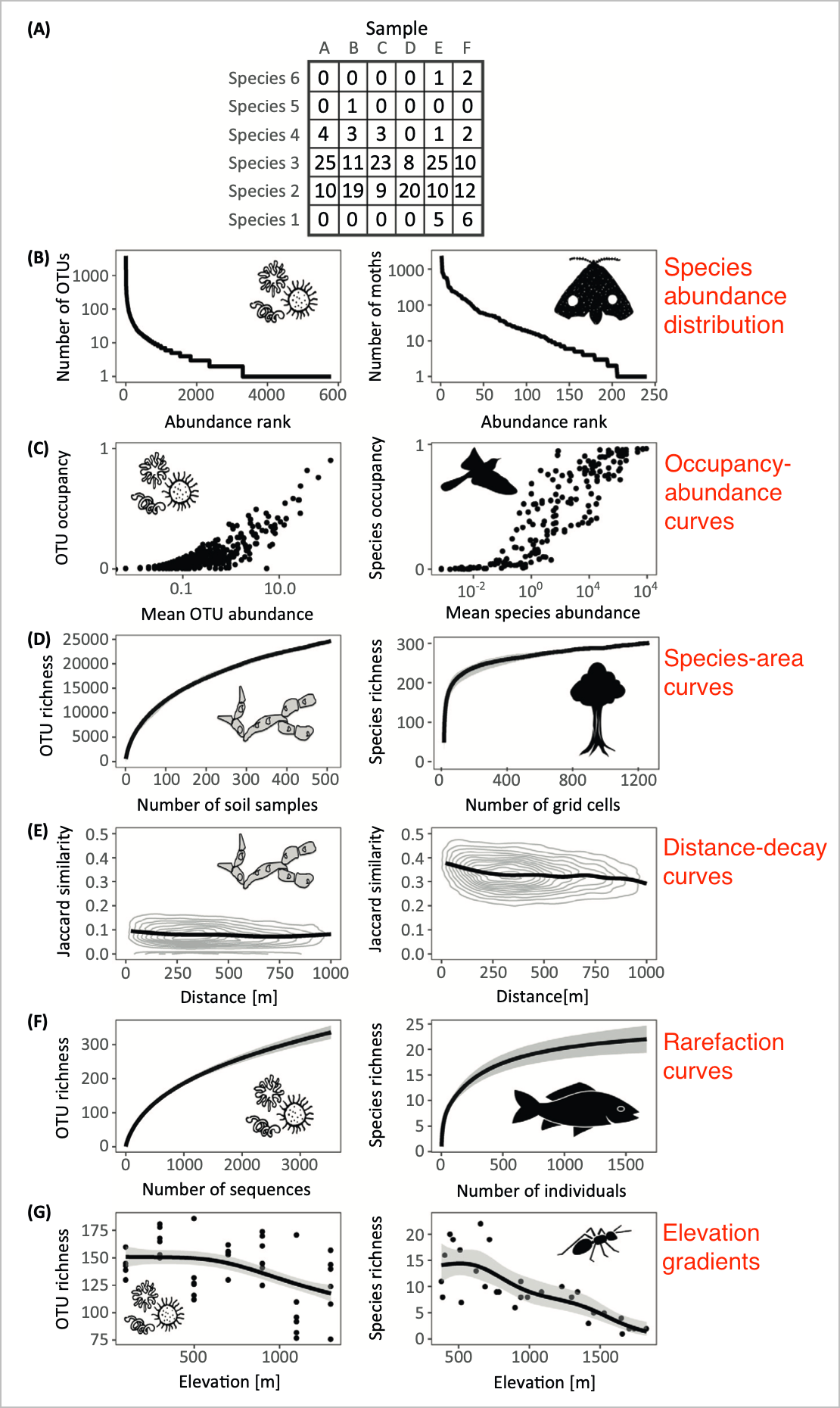
Species Abundance Distribution
Species Abundance Distribution (SAD) describes how individuals are distributed among all the species within our sampled community. It tells us about the patterns of species dominance and rarity—this information relates to a more nuanced understanding of ecological dynamics, community structure, and the mechanisms driving biodiversity. SAD curves can be made for any community for which we have species lists with their abundances.
The first form of SAD is the one given by Shade et al. (2018), which shows the number of individuals (N) of each species in a sample. It is formed by log(N) (on y) as a function of species rank (on x), with species ranked 1 most abundant and plotted on the left and decreasing to less abundant species on the right. Matthews and Whittaker (2015) call this form of SAD a Rank Abundance Distribution (RAD) curve. The profile of this relationship can be variable, but in general it shows that only a few species attain a high abundance while the majority of them are rare. This is a typical pattern in most communities and is often referred to as a log-normal distribution, but some other models can also be used to describe these SADs. The type of model applied to a SAD curve may reveal different ecological processes and mechanisms. Matthews and Whittaker (2015) argue that the form of the SAD and the model that describes its form can be used to develop suitable ecosystem health assessment insights and develop applicable conservation and management strategies.
References
Reuse
Citation
@online{smit,_a._j.2024,
author = {Smit, A. J.,},
title = {Lecture 3: {Species} {Distribution} {Patterns}},
date = {2024-07-22},
url = {http://tangledbank.netlify.app/BDC334/L03-structure.html},
langid = {en}
}